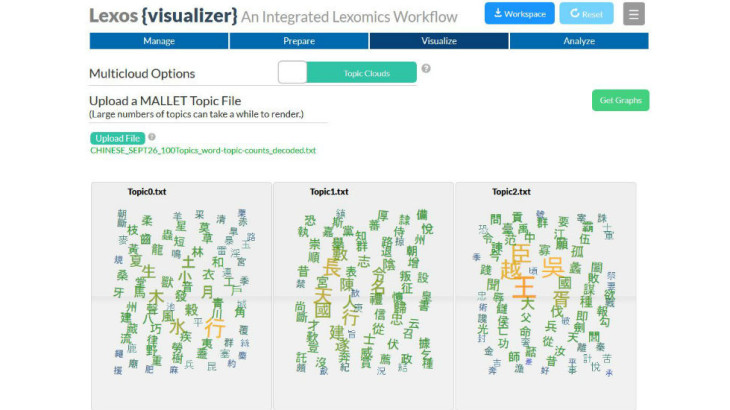
Some Background
Topic modelling is gaining increasing momentum as a research method in Digital Humanities, with MALLET as the general tool of choice. However, many would-be topic modellers have struggled to make effective use of MALLET’s output, which is raw data. In fact, there has been a growing movement to devise methods of visualising topic modelling data generally. A while back, Elijah Meeks had an idea for generating topic clouds: separate word clouds for each topic in the model. [I can’t seem to access his original blog post, but here is his code on GitHub.] Although word clouds have their problems as visualisations, Meeks speculated that they were particularly effective for examining topics in a topic model. Indeed, others have used word clouds to visualise topic modelling results, most notable Matt Jockers in the digital supplement to his Macroanalysis. One of the things I liked about Meeks’ implementation using d3.js was that it placed the clouds next to each other so that they could be compared.
I quickly transferred this idea to our work on the Lexomics project, and our software Lexos. In Lexomics, we frequently cut texts into chunks or segments, which can then be clustered to measure similarities and differences.… Read more…


