


Update March 15 2016: This content was selected for Digital Humanities Now by Editor-in-Chief Joshua Catalano based on nominations by Editors-at-Large: Ann Hanlon, Harika Kottakota, Heather Hill, Heriberto Sierra, Jill Buban, Marisha Caswell, Nuria Rodriguez Ortega. The slides have now been integrated, and they can also be seen in a reveal.js presentation here.
This is an edited version of a talk I gave at UC Irvine on February 5, at a Symposium on Data Science and Digital Humanities organized by Peter Krapp and Geoffrey Bowker.
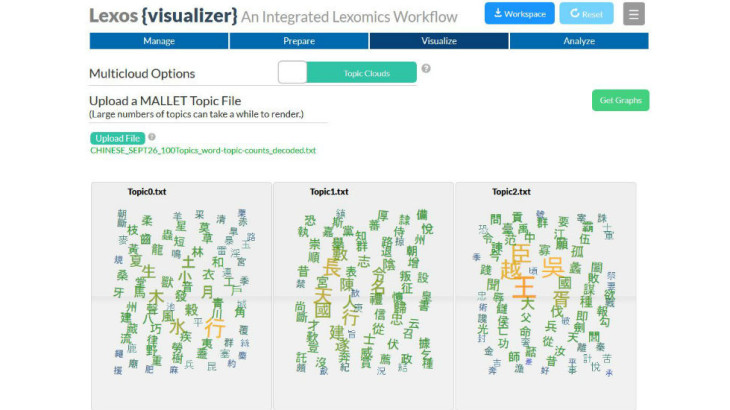
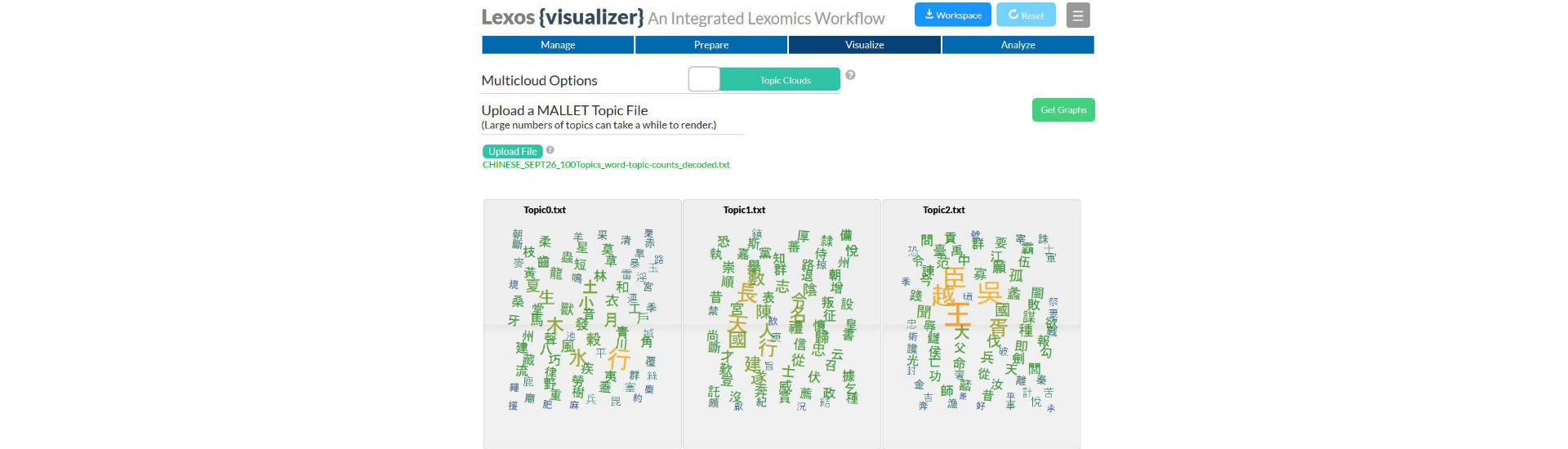
I’ve made the focus of my talk Digital Humanities projects involving small and unusual data. What constitutes small and unusual will mean different things to different people, so keep in mind that I’ll always be speaking in relative terms. My working definition of small and unusual data will be texts and languages that are typically not used for developing and testing the tools, methods, and techniques used for Big Data analysis. I’ll be using “Big Data” as my straw man, even though most data sets in the Humanities are much smaller than those for whom the term is typically used in other fields. But I want to distinguish the types of data I will be discussing the from large corpora of hundreds or thousands of novels in Modern English which are the basis of important Digital Humanities work.… Read more…