Some Background
Topic modelling is gaining increasing momentum as a research method in Digital Humanities, with MALLET as the general tool of choice. However, many would-be topic modellers have struggled to make effective use of MALLET’s output, which is raw data. In fact, there has been a growing movement to devise methods of visualising topic modelling data generally. A while back, Elijah Meeks had an idea for generating topic clouds: separate word clouds for each topic in the model. [I can’t seem to access his original blog post, but here is his code on GitHub.] Although word clouds have their problems as visualisations, Meeks speculated that they were particularly effective for examining topics in a topic model. Indeed, others have used word clouds to visualise topic modelling results, most notable Matt Jockers in the digital supplement to his Macroanalysis. One of the things I liked about Meeks’ implementation using d3.js was that it placed the clouds next to each other so that they could be compared.
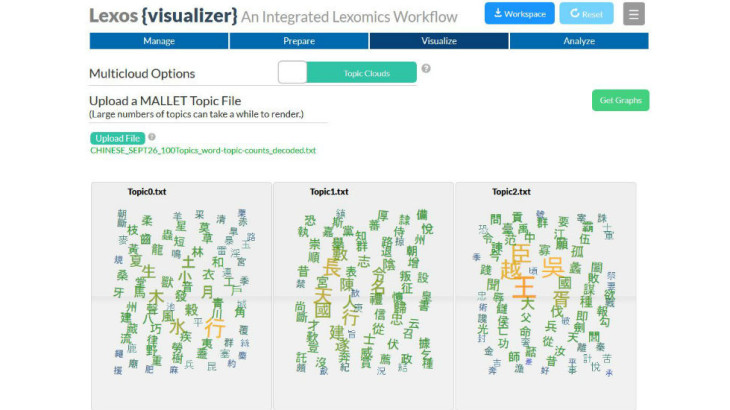
I quickly transferred this idea to our work on the Lexomics project, and our software Lexos. In Lexomics, we frequently cut texts into chunks or segments, which can then be clustered to measure similarities and differences. I thus borrowed Meeks’ topic clouds idea and created the Multicloud tool in Lexos to provide a visual way to compare the segments. Lexos allows you to slice and dice your texts and then generate word clouds of the resulting chunks–all in a web-based interface. For a long time now, I have thought it would be great to use Lexos as a tool for generating topic cloud visualisations as well.
However, this is not straightforward. In order to create word clouds from MALLET-generated topics, you need to transform the data from MALLET’s not-very-friendly output format to something that can actually be read by the d3.js script. In practice, it requires some programming skills. Lexos to the rescue! We’ve now given Lexos the ability produce topic clouds directly from MALLET data.
How to Do it Yourself
A word of warning. We’re still working on the user interface, so some of the specifics of the procedure may change slightly.
Before you begin, you will need MALLET to produce a file containing the word counts of each word in each topic. Many people don’t get this data. The GUI Topic Modeling Tool doesn’t produce it, so you have to use the command line version of MALLET. Even then, you might still not be getting the right data. If, like many, you use the code in the tutorial provided by The Programming Historian, you are not going to get the data you need. But it’s an easy fix.
Update (11 June 2015): Lexos can now process the MALLET “output-state” file, which everybody produces, whether they are following the Programming Historian tutorial or running the GUI Topic Modeling tool. It’s probably still a good idea to follow the instructions below because you have to unzip the “output-state” file before uploading it to Lexos (I recommend 7zip for this), and the file is much larger, which will increase the uploading time.
Let’s take a look at the command provided by The Programming Historian:
|
1 |
bin\mallet train-topics --input tutorial.mallet --num-topics 20 --optimize-interval 20 --output-state topic-state.gz --output-topic-keys tutorial_keys.txt --output-doc-topics tutorial_composition.txt |
The last portion is a good illustration of how MALLET commands work. You have a flag like –output-doc-topics, which tells MALLET to produce a file containing the topics in each document, and then you give it a filename, in this case, tutorial_composition.txt. So we need to tell MALLET to create a file with the word counts in each topic. The flag for this is –word-topic-counts-file. So simply add this and a filename to the end of the MALLET command:
|
1 |
bin\mallet train-topics --input tutorial.mallet --num-topics 20 --optimize-interval 20 --output-state topic-state.gz --output-topic-keys tutorial_keys.txt --output-doc-topics tutorial_composition.txt --word-topic-counts-file word_topic_counts.txt |
Now run MALLET. You’ll get a word_topic_counts.txt file along with the rest of the topic model data. This is the file you’ll feed into Lexos.
Typically, you upload texts to Lexos for further processing, but since you already have your data file, you can head straight over to the Lexos Multicloud tool, where you can upload your MALLET file. (Note: At the moment, we’ve placed the upload function directly on the Multicloud page; that might change in the future.) You’ll see something like this:
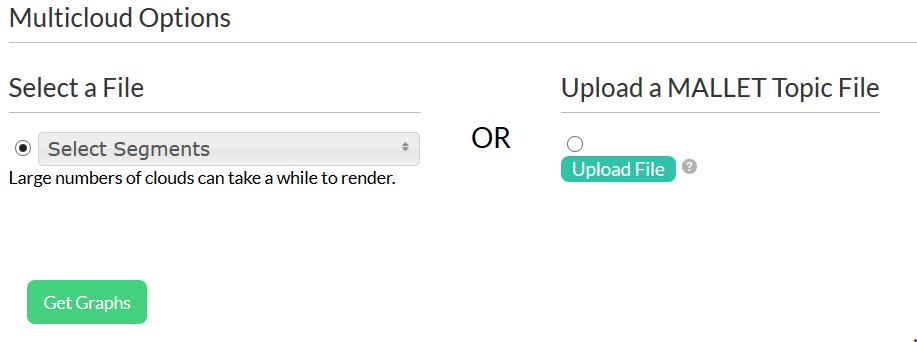
Click the radio button under Upload a Mallet Topic File, and then click the Upload button. Select your word_topic_counts.txt file or output-state.txt file and upload it.
Update for July 23, 2015: In Lexos v2.5 there is now a toggle button when you first load Multicloud. Click the button where it says “Document Clouds”, and the toggle will switch to “Topic Clouds”. You can then upload your file.
Next click Get Graphs. If you have a large number of topics, it may take awhile for the graphs to appear. Be patient. But that’s it!
Now for the bonus. If you mouse over the words, you’ll be able to see the word counts in tooltips. You can also re-order the clouds by dragging and dropping them into different locations. This is valuable because you can bring topics that might be sequentially distant (e.g. Topics 1 and 100) into greater proximity for easy comparison. Update (June 11 2015): I have learnt a lot about d3 word clouds over the past few months. I hope to have a follow-up post about them in the near future.
Update: I am constantly asked how to specify the number of keywords given in the MALLET output file, and I can never remember the answer. So I’m adding it here to make it easy to find. The argument
|
1 |
--num-top-words 15 |
in the MALLET train-topics command will output 15 keywords.